My non-exhaustive Foundry wishlist
04/16/2024
Foundry is passing an inflection point. Palantir used to have to sell it into existing large enterprises, but startup developers are starting to choose it on their own.
I left Palantir 3 years ago, and I’ve been religiously following the announcements page and documentation since they launched. I can feel the product velocity, and more importantly the acceleration. The core product developments in the time since I left have been huge. Pipeline builder is awesome. Workshop still has flaws but is so powerful for internal apps.
What I’m most excited about is the emerging set of developer tools. I’m seeing startups deciding to go all in Foundry because of the new Ontology SDK (OSDK). Combined with the rest of the platform it now makes sense to build your software layer on top of Foundry rather than from scratch on top of a public cloud, even with its current papercuts. I would not have recommended someone build their business on top of Foundry when I left Palantir, but I would today. A lot of my perspective comes from working on building a software-defined business at Chapter, where we were the first Foundry startup customer.
All this being said, there are still a bunch of things Foundry needs to achieve its vision of being a single, programmable, control plane for your entire organization.
Conflict resolution
The Foundry documentation maintains a bit of history on the Ontology backend architecture here. The architecture aims to support Foundry itself as a system of record, as well as interoperability with existing systems of record. It supports interoperability via hydration of data from other systems, and writeback that captures and indexes user edits and triggers corresponding writes to other systems via webhooks. In this model we have the most recent data from the source system as well as Foundry's understanding of edits, and so we need some way to resolve conflicts between the two.
Historically Foundry has only shipped with an "edits-win" strategy where user edits are replayed on top of the source system data. This strategy is honestly pretty useless because once a record has been edited in Foundry, there is no way for newer edits within the source system to be reflected, so the two systems can't really interoperate.
I've been begging for improvement here for years and there is finally a new strategy in beta! This new strategy decides whether to prefer Foundry's edits or the source system data based on a timestamp property. Foundry's edits here essentially act as optimistic updates until we catch up with the source system. This strategy should work really well for most use-cases.
Transaction isolation
There is an inherent difficulty in Foundry providing transactional guarantees given it is usually supplying a
single control plane over distinct transactional systems that are each acting as a source of truth. That said,
within Foundry's writeback system there should be clear documentation of the transaction isolation guarantees.
My guess based on memory and some
off-hand comments in the documentation
are that the guarantees are equivalent to READ COMMITTED in traditional database management systems (e.g.
PostgreSQL). I think READ COMMITTED is fine
for most use-cases, which is why it's the default transaction isolation level in both PostgreSQL and MySQL.
Whatever the guarantees are, they need to be clearly documented so developers building mission-critical
systems on top of Foundry are operating with the correct assumptions.
Complex property types
Right now the only complex property type that Foundry allows are one-dimensional arrays of primitive types. In the absence of nested array and struct property types, you are essentially forced to model your data relationally. For example, if I'm modeling customer orders, I need separate object types for orders and line items.
This presents a problem. Assuming that Foundry's consistency guarantees are equivalent to READ COMMITTED as
explained above, you're guaranteed consistency at the level of a single record -- quoting
this unrelated documentation,
"READ COMMITTED is appropriate when each row of data is processed as an independent unit, without reference to
other rows in the same or other tables." In the case of customer orders, we should have consistency between an
order and its line items. That is, the
consistency boundary is really at the level of the
order. What this means is Foundry really doesn't have any way to model our data and maintain the consistency
guarantees we want.
My proposal for solving this is complex property types! Our model would include a single order object type, with a property that is an array of line items each with a product code and quantity and price. This would let us model our data with proper consistency guarantees. It would also alleviate other issues, for example awkwardness around needing to have primary keys for line items when they don't really need to be globally addressable.
PostgreSQL for example supports composite types so I don't think this is a stretch. The main implementation challenge would likely be updating all of Foundry's core products to understand complex property types, but given how important this is for building correct systems I think it's worth the effort.
Value types improvements
I'm super excited about the recent introduction of value types. We have a ton of what we call “constrained types” at Chapter, loosely based on Scott Wlaschin’s writing on his blog and in his book. There's another good post here explaining the motivation.
There are a few key things I would like to see in subsequent iterations.
Required-ness
Always missed this in base types which are always nullable, and value types seems like a natural place to support this.
Periodicity for temporal types
At Chapter we have a FirstDayOfMonth type used mostly for Medicare policy effective dates that are always on
the first day of a month. There's no way to model this right now with the available
constraints. I think we
need some way to encode periodicity similar to what you see when setting up calendar invites for temporal
value types to actually be useful.
Logic functions for parsing
Without support for general logic, the set of types that value types will be able to actually support will be
quite small. A fun example from Chapter that comes to mind is our NPI type.
NPIs have some
complex logic for allowed values and include a check digit.
I imagine a new Functions on Objects
(FOO) decorator is a natural way to support this type of logic, and the function should return a Result with
either the parsed value or an error.
Nominal typing in FOO/OSDK
There should be bindings for accessing value types in FOO and OSDK that provide nominal typing. Part of the
motivation for value types is to "make illegal states unrepresentable". Let's say I have a function that takes
in a phone number and returns the estimated timezone. If the function can take in a PhoneNumber type that is
guaranteed to be a phone number rather than a string, that means I don't need to defensively code within my
function. I know I'm getting a phone number, and I can just grab the area code and use it to estimate the
timezone. Typescript doesn't cleanly support nominal typing -- there has been a
GitHub issue on the subject open for 10 years now. There
are a few ways to fake it though. The main downside
to type brands as a solution is they feel like black magic to write and maintain, but a computer would be
generating them here so they are probably the right choice. And Palantir already uses type brands internally
in some places so they won't be unfamiliar.
Marketplace features
I'm super excited about Marketplace. There were a couple false starts on this idea within Foundry during my time at Palantir (the first failed iteration was called "Templates", the second "Archetypes") but it seems like things are finally coming together.
There are a couple things that need to happen for Marketplace to really take off:
- Custom frontend apps in Marketplace as supported resources. These can be deployed using the same mechanism as the newly launched web hosting support.
- Billing! A return to non-subscription software would be cool and feasible for a lot of Foundry-native apps because the app vendor isn't responsible for hosting in this model and is truly just shipping code.
I think there's potential for an explosion of Foundry-native SaaS offerings. Without having to worry about distribution, payment, and hosting, small teams of developers will be able to run SaaS businesses that focus entirely on product.
Client state management
This is my favorite idea to talk about, it's very low-level but very important. Speaking from doing a ton of frontend work over the last 10 years, client state management is easily the hardest part of building applications.
Imagine I have a task-management app that looks like this:
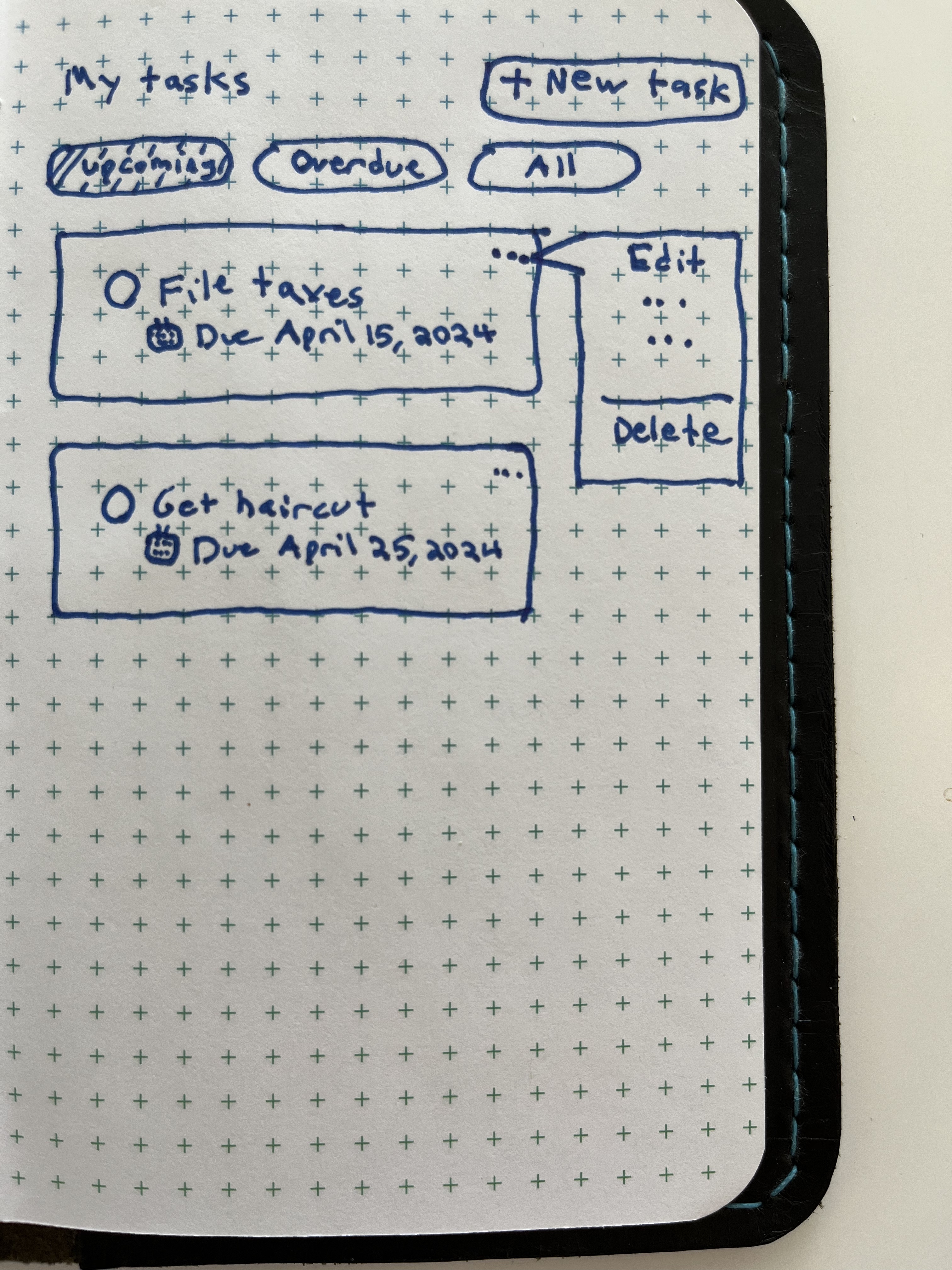
Creating a new task with a future due date should result in the task showing up in the correct position in the Upcoming list as well as the All list. Editing an overdue task to a future date should result in the task being removed from the Overdue list and added to the correct position in the Upcoming list. If my tasks are paginated from the server, any mutation adding a task to any list should take into account whether the task should actually show up given our current pagination state, or should be left to be loaded in after a future pagination request.
Normally a developer needs to write all this very mechanical glue code to get a nice user experience. Often instead they will just refetch all the data on the page after a mutation because it's easier to code, but the user experience is poor.
The Ontology as a set of primitives actually enables us to automate all this mechanical client state management code. The Ontology has a first-class notion of filters and sorts, and our Upcoming and Overdue and All lists can be defined with those filter and sort primitives. When we run our "Create task" Action, our client state management engine can evaluate which filters the new task matches purely on the client-side and make sure it ends up in the right lists at the right positions. Since our Action here is simple we can define it using a "Create object" rule, which means we can also easily process the edit optimistically on the client-side. So our "Create task" action and its other effects on lists on the page can be executed entirely optimistically on the client-side, providing the UX of a desktop application with no manual glue code. There is the opportunity to create an incredible client state management SDK here that lets developers think purely about Actions and queries, and then automatically handles all the tricky mechanical parts. Taking this sort of logic out of the hands of developers would let them just focus on implementing designs and building great products. Workshop actually does a version of this, which is the real reason why Workshop is so pleasant to use compared to other no-code app builders -- you don't have to think about client state, it just gets handled automatically.
My short-term proposal here is a Relay-compatible GraphQL API layer over the Ontology
(similar to the existing REST layer), and then an automatically
generated SDK on top of Relay that for each Action creates a wrapper around
useMutation that implements a
Relay updater
to provide all the glue code. We could alternatively build a native client state management stack on top of
the Ontology specification, but Relay is already so mature and optimized, and GraphQL already has so much
tooling around it that as a matter of practicality this route makes a lot of sense in the short run.
This is the real path for building high-quality frontend apps on top of Foundry. OSDK is cool for backend logic but nobody is actually going to build a React app of sufficient complexity on top of it (sorry). You would be left to roll client state management yourself which is actually the hardest part of building an app. But again the Ontology is uniquely suited to remove the hard stuff here with its primitives!
I'm planning to turn this topic into a full post because there's a ton more to dive into here.
End-user authentication/authorization
There's a gap right now in Foundry around end-user authentication and authorization for B2C businesses that build their API layer on top of Foundry. At Chapter we manage a ton of complexity behind the scenes for our customers, much of it in Foundry. For example, we have several internal applications built on Foundry that allow us to maintain a comprehensive understanding of all the Medicare policies we hold. We want end-users to have access to some subset of this data, for example to pull in their own Medicare policy in a mobile app where they can see a digital card wallet and utilize services and benefits covered by their policy.
Let’s say our end-users authenticate using a service like Auth0. Ideally there would be some way to sync our Auth0 users as super-limited Foundry users that only have API access to a single developer console application and can't actually log into the platform. Then Foundry's first-class row-level and column-level access controls should just work. Right now if you want to do something like this you have to build a custom gateway outside of Foundry where you manage your own authentication and authorization logic. This is complicated and slow -- every request has to go through your own authentication and authorization layer as well as Foundry's -- so Foundry should have something native here.
Unification of FOO and OSDK
There is a weird split right now between FOO and OSDK. They are serving largely the same purpose but have different-looking SDKs. All FOO functions are completely isolated and cannot invoke each other, but OSDK logic can call all FOO functions. The dependency management problem here is complex which is I'm sure why FOO to FOO invocation has been punted, but Palantir has a better understanding of this problem than anyone and is well-equipped to solve it.
The ideal end-state here probably looks something like FOO/OSDK being unified into one, which I'll call OSDK here. I have the option to deploy my OSDK functions inside of Foundry, and OSDK functions can invoke each other. I can build and publish my OSDK functions locally via my own CI. I can also use OSDK outside of Foundry for externally-hosted applications.
Infra-as-code for Foundry resources
I want to be able to define certain Foundry resources via infra-as-code tools (e.g. Terraform and Pulumi).
One category of resources I want to be able to define are data ingestion resources like sources, syncs, and datasets. If I'm already defining my other cloud resources where my data lives (e.g. databases, buckets, pub/sub topics) with an infra-as-code tool, it would be super easy to wire them up to Foundry without needing to manually create connections and copy/paste credentials. Imagine something like this with Pulumi:
import * as pulumi from "@pulumi/pulumi";
import * as aws from "@pulumi/aws";
import * as foundry from "@pulumi/foundry";
const bucket = new aws.s3.Bucket("bucket", {
bucket: "my-bucket",
acl: aws.s3.CannedAcl.Private,
versioning: {
enabled: true,
},
});
const user = new aws.iam.User("service-user");
const accessKey = new aws.iam.AccessKey("service-user-access-key", {
user: user.name,
});
const policy = new aws.iam.Policy("service-user-bucket-policy", {
user: user.name,
policy: JSON.stringify({
Version: "2012-10-17",
Statement: [
{
Action: ["s3:GetObject", "s3:ListBucket"],
Resource: [bucket.arn],
Effect: "Allow",
},
],
}),
});
const source = new foundry.data.S3Source("bucket-source", {
url: pulumi.interpolate`s3://${bucket.name}/`,
endpoint: "s3.amazonaws.com",
credentials: {
accessKeyId: accessKey.id,
secretAccessKey: accessKey.secret,
},
});
const dataset = new foundry.data.Dataset("dataset", {
path: "/MyOrganization/MyProject/raw/data",
});
const sync = new foundry.data.Sync("bucket-sync", {
sourceRid: source.rid,
datasetRid: dataset.rid,
transactionType: "SNAPSHOT",
schedule: "0 9 * * *",
});More importantly, the other category of resources I want to be able to define are Ontology primitives like Object Types and Actions. For code-first Ontology use-cases this would actually make staging environments feasible to maintain, which is important for mission-critical workflows. It would also enable modern development workflows like preview deploys.